Now accepting design partners
The Runtime for Liquid Compute
Compute flows to wherever it’s cheapest, fastest, and smartest to run.
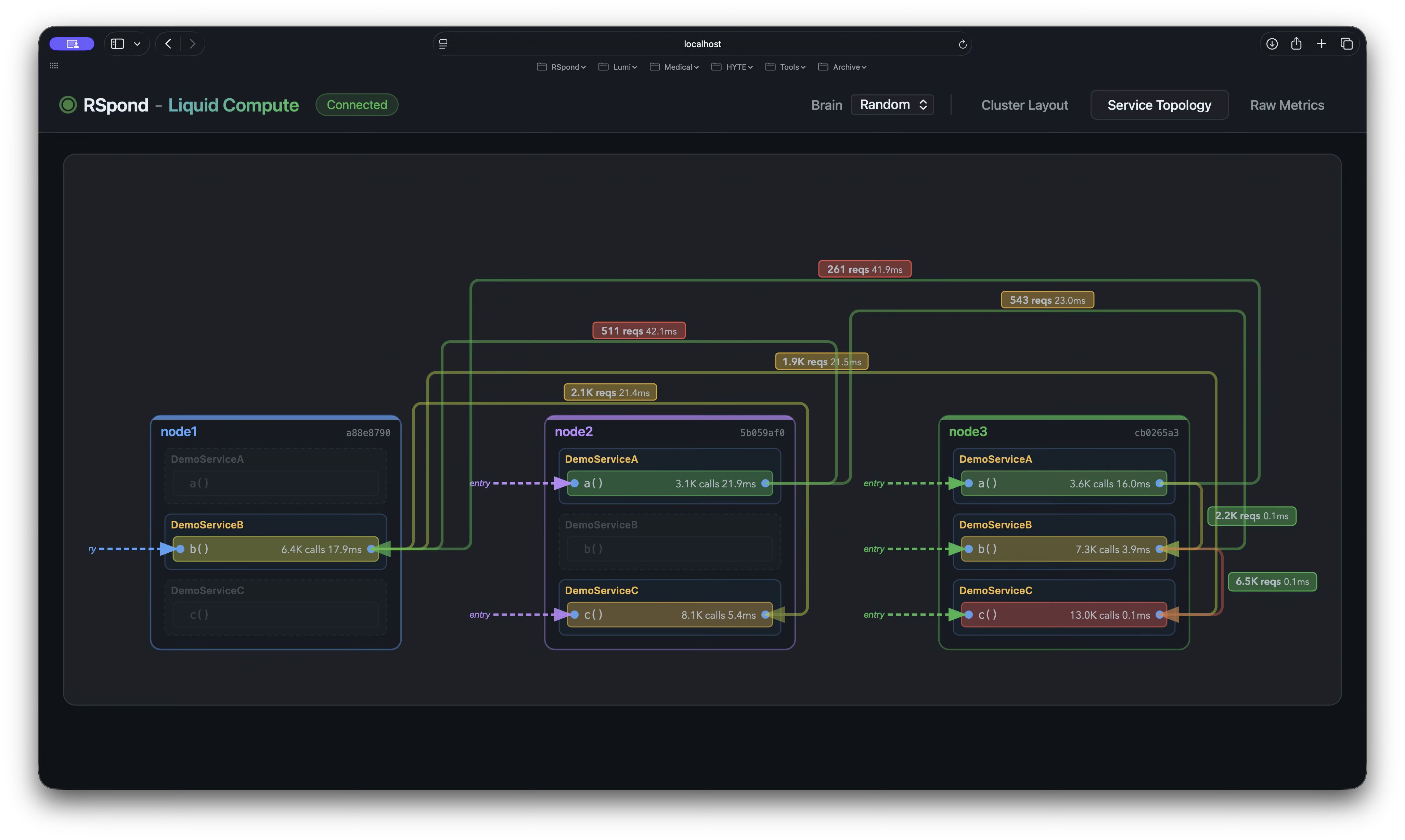
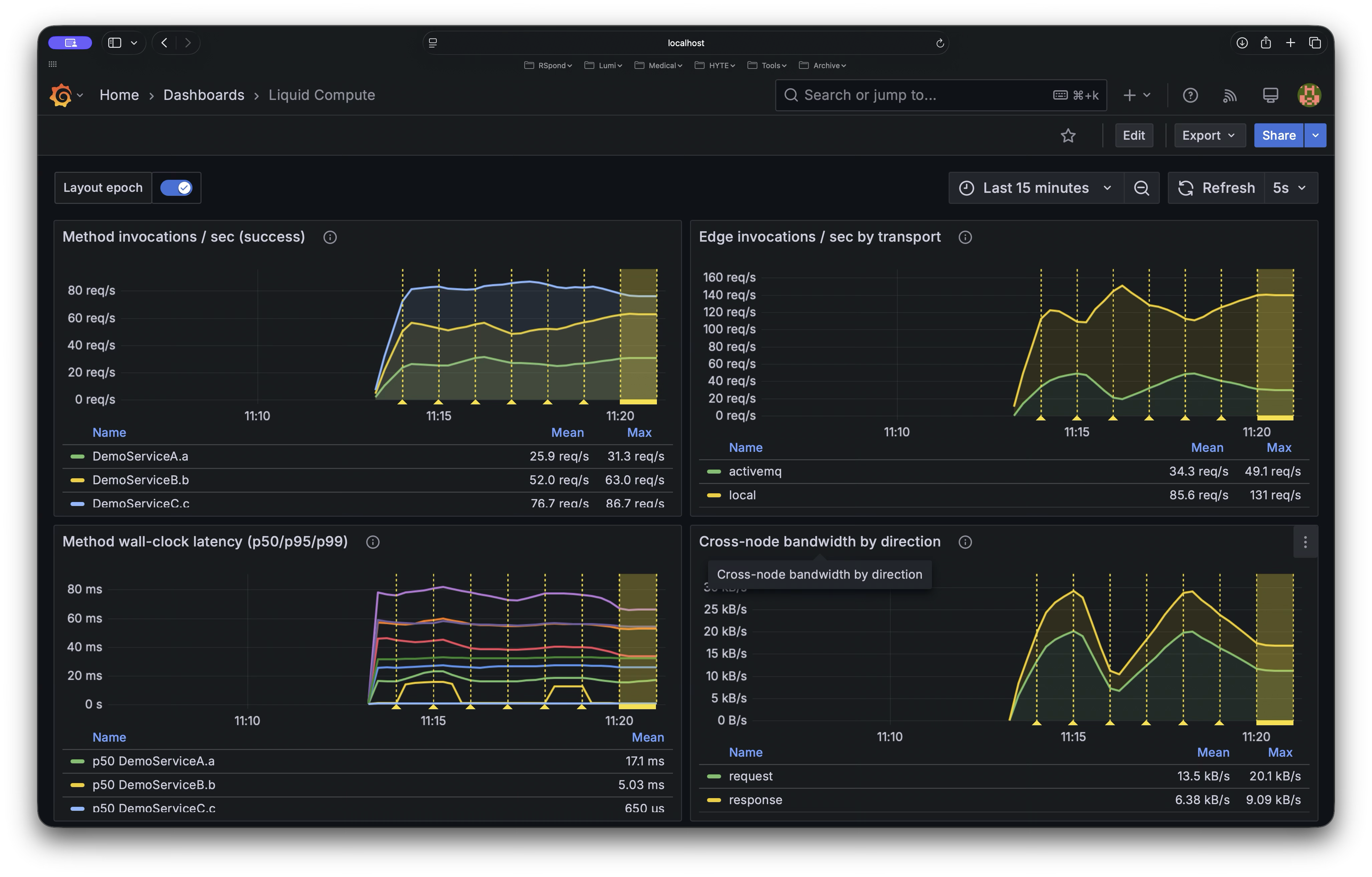
A scheduling brain profiles every Spring service, measures the call graph, and continuously re-packs services across nodes, regions, and providers—with zero redeploys and no changes to application code. One annotation. Your existing Spring beans. That’s it.
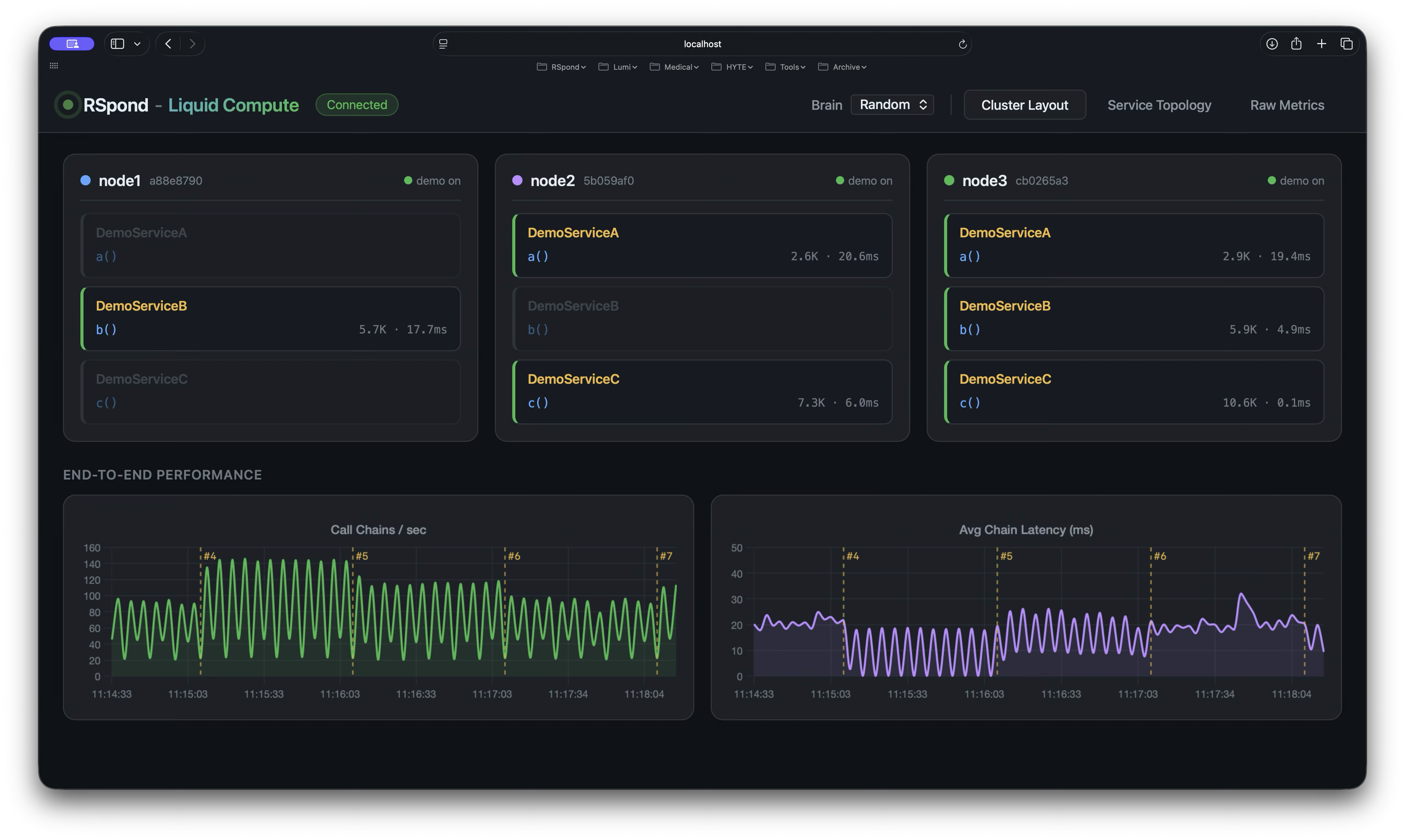 LIVE · 3 NODES · 17K+ CALLS/SEC
LIVE · 3 NODES · 17K+ CALLS/SEC