Why now
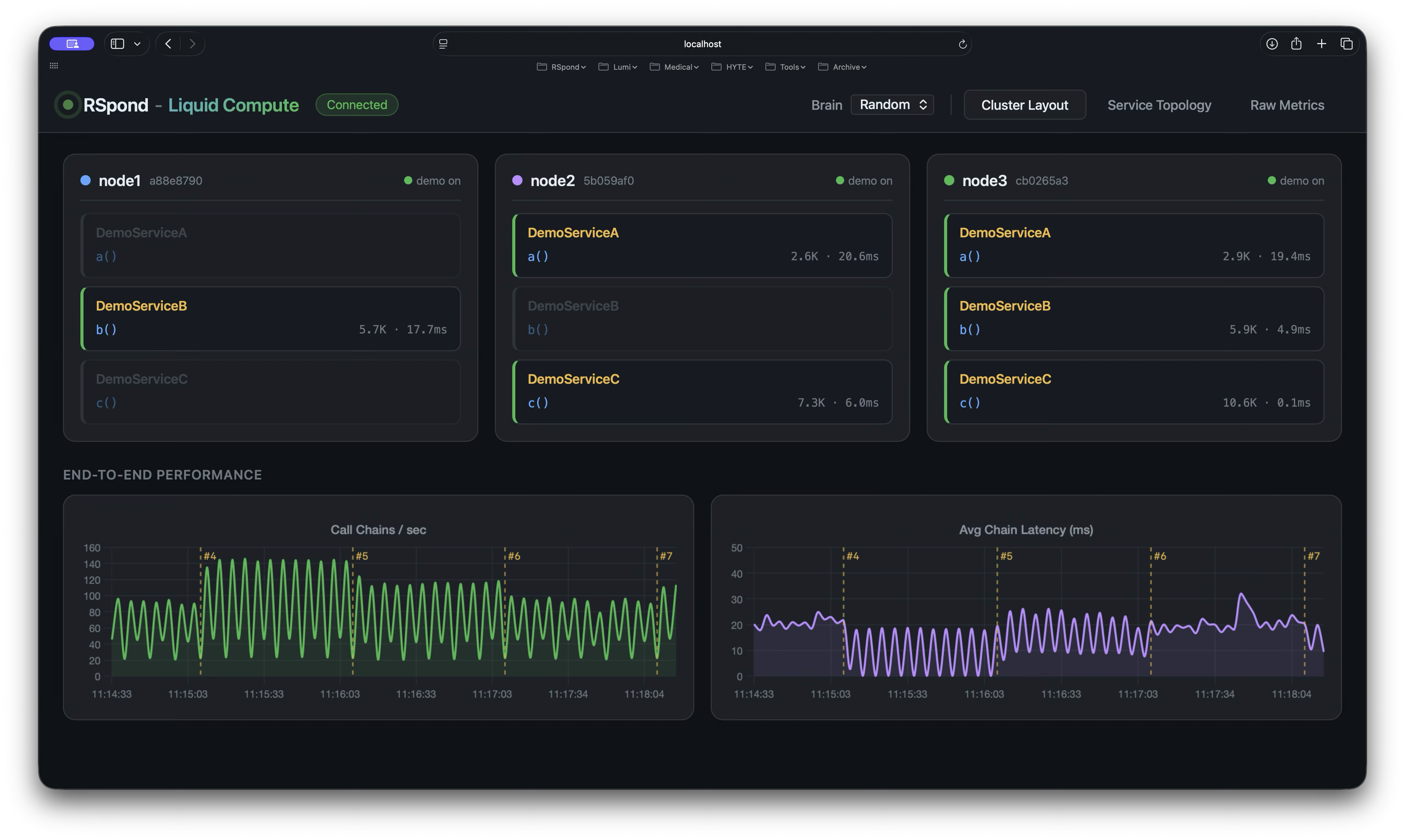
The cloud was built to hold workloads. We’re building one to let them flow.
AI coding is detonating service counts. Containers are 13 years old. The tools that worked for a dozen services don’t work for a hundred. Liquid Compute makes services flow across nodes, regions, and providers at runtime — no redeploys, no downtime, no team coordination. We’re looking for a handful of teams to prove that out alongside us.
Partner profile
Who we’re looking for
Platform engineering teams running Java/Spring services at scale, where at least one of the following is unmistakably true:
FINOPS
Cloud spend is a board-level concern. You suspect significant overprovisioning across your service fleet and quarterly cost reviews aren’t closing the gap.
OPS
Service placement is a recurring headache. Rebalancing means redeployment, coordination, and downtime risk — so it doesn’t happen often enough.
SOVEREIGNTY
Multi-cloud or data residency. Deployment complexity from regulatory boundaries or provider diversity is outgrowing manual processes.
TOPOLOGY
Call graphs are non-trivial. Static placement leads to hotspots, chatty cross-AZ traffic, and wasted bandwidth that static autoscaling can’t resolve.
VELOCITY
You’re shipping services faster. AI-assisted development is multiplying service count and your ops tooling can’t keep up with the granularity.
STACK
Java and Spring at scale. A meaningful share of your service estate runs on the JVM — the surface where @Liquid annotations make a service instantly portable.
The exchange
What partners give. What partners get.
Design partnerships work when the value flows both ways. We’re explicit about what we ask and what we deliver — no surprises on either side.
What we ask
Real workloads, real candor.
- Run it on real (or realistic) traffic. A staging cluster mirroring production volume is enough to start.
- A regular feedback cadence. Typically a 30–60 minute call every two weeks with your platform lead.
- A technical point of contact. A platform engineer or architect who can evaluate and provide hands-on feedback.
- Candor about pain points. What broke, what was confusing, what didn’t make sense. Polite feedback isn’t useful feedback.
- Willingness to be a case study. When the time is right — on your timeline and with your approval — help us tell the story.
What you get
Early access. Direct line. Pricing locked.
- Early access to the framework as it moves toward production readiness — features land in your cluster before public release.
- Direct engineering relationship. Slack with the team building the brain. No tier-one ticket queue.
- Roadmap influence. Your pain points determine what we build next. The brain’s next strategy can be the one you need.
- Hands-on integration support from the engineering team during onboarding.
- Design partner pricing. Preferred terms locked for the duration of the program and beyond.