Today, placement is decided once at deploy time and renegotiated by migration project. Tomorrow, placement is a continuous runtime decision—and the cheapest, fastest, most sovereign node wins every minute.
Why now
This is not a problem to schedule for next year. Three forces are converging right now, and each compounds the next.
AI coding detonates service count
Code is suddenly cheap and plentiful. Enterprises will ship 10x more services—and spend 10x more on compute to run them. Every efficiency point compounds. The volume of services is about to overwhelm the tools designed for a simpler era.
Containers show their age
Docker is 13. Kubernetes is 12. Both were designed for the cloud era—static footprints, one region, one vendor. Platform teams are openly shopping for what comes next. The container era taught the industry how to package code; it never taught compute how to move.
New apps need new ops
Current infrastructure can't manage the complexity and granularity of workloads interacting nonlinearly with service infrastructure. The tools that worked for a dozen services don't work for a hundred—and AI-assisted teams are about to ship a thousand.
Cloud resource utilization today is where Java performance was before HotSpot: provisioned statically, optimized manually, wasting resources by default. Liquid Compute applies HotSpot's philosophy—observe and optimize continuously at runtime—to the entire compute estate.
Four capabilities, one runtime
Liquid Compute is one annotation away. Underneath, it delivers four capabilities the cloud era never gave you.
01 · Commoditize Providers
Any premise, one cluster.
AWS, GCP, Azure, and on-prem share a single routing table. When a provider degrades or a regulation binds data to a jurisdiction, the brain treats it as a hard constraint—services flow elsewhere automatically.
02 · Distribute Transparently
Annotate. That's it.
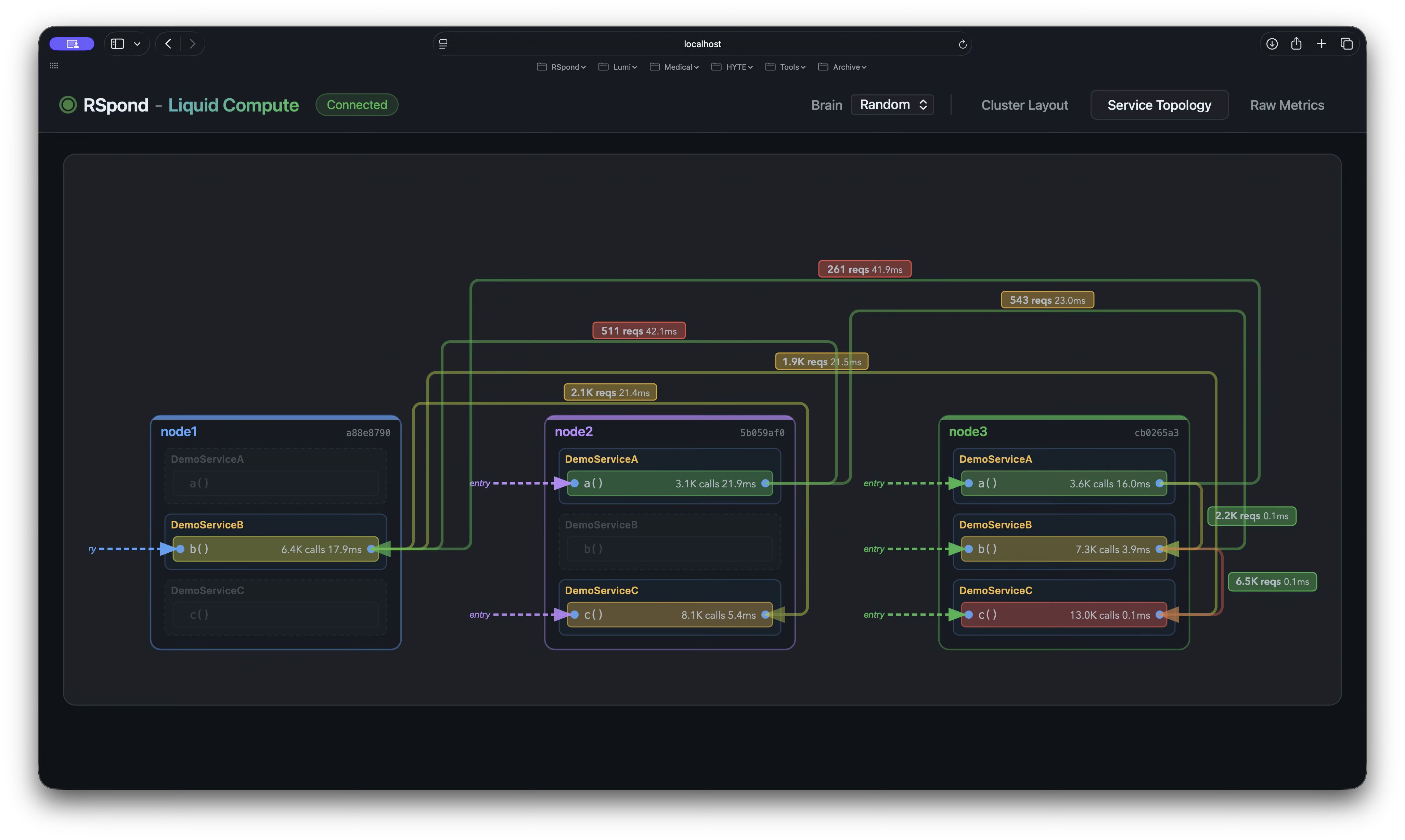
Developers annotate a Java interface with @Liquid and implement it as a normal Spring bean. The framework routes every method call. No sidecar, no separate control plane, no protocol to learn.
03 · Rebalance Dynamically
Services move. Nothing restarts.
The routing table rewrites at runtime. New nodes activate before old ones drain. The stability invariant guarantees at least one active replica at all times. Zero downtime, zero redeploys, zero team coordination.
04 · Optimize Cost First
FinOps, continuously.
Profiled services packed like bins—spot prices and call graphs are inputs, not afterthoughts. This isn't a reporting tool that tells you what you spent. It's a runtime that cuts spend dynamically.
One platform. One invoice. Four budget lines replaced.
Each incumbent today owns one budget line. Liquid Compute collapses four of them into a single runtime—and operates at a layer none of them can reach.
| Budget line |
What you buy today |
Why Liquid Compute replaces it |
| Cost / FinOps |
Kubecost, CloudZero, Apptio Cloudability |
We don't just report. We cut spend dynamically. |
| Autoscaling |
Karpenter, CAST AI, Spot by NetApp |
We route at the method level, not the container. No pod churn. No cold starts. |
| Service Mesh |
Istio, Linkerd, Consul |
Services move at runtime. Meshes are fixed. No sidecars, no CRDs, no control-plane ceremony. |
| Distributed Runtime |
Akka, Erlang/OTP, Orleans |
One annotation on existing Spring beans. No language or framework rewrite. |
Liquid Compute operates at the application layer, inside the JVM. It sees what Kubernetes and service meshes cannot: individual method calls, call-chain topology, per-method CPU time, and cross-service affinity. It's not a replacement for Kubernetes—it's the layer above, the application-level intelligence that tells infrastructure where computation should actually happen.
Who it's for
◆
Platform engineering teams
2–16 person teams running Java/Spring services at scale. You use Kubernetes and service meshes today but lack fine-grained, real-time control over where computation happens. You own cloud spend and reliability.
◇
Application developers
You want distributed execution without the complexity. @Liquid gives you distribution as a capability, not an architectural commitment. The same code runs on one node or across a hundred.
Design partner profile
Organizations where cloud spend is a board-level concern, where service placement is a recurring operational headache, where data sovereignty creates deployment complexity, or where cross-service call patterns cause hotspots that nobody can diagnose from logs.