The Developer Experience
One annotation on the interface. The implementation is a normal Spring bean — no base classes, no framework APIs, no awareness of distribution. Adoption is a Maven dependency, not a migration.
The interface
One annotation. A standard Java interface. Nothing else.
PricingService.java
@Liquid(version = "1.0.0")
public interface PricingService {
Price calculatePrice(Order order);
}
The implementation
A normal Spring bean. Constructor injection, business logic, return a value. Nothing here knows the call may cross a node boundary.
PricingServiceImpl.java
@Component
public class PricingServiceImpl implements PricingService {
private final Catalog catalog;
private final Promotions promotions;
public PricingServiceImpl(Catalog catalog, Promotions promotions) {
this.catalog = catalog;
this.promotions = promotions;
}
public Price calculatePrice(Order order) {
// Business logic — no awareness of distribution
var basePrice = catalog.lookup(order.itemId());
var discount = promotions.apply(order.customerId(), basePrice);
return new Price(discount, order.currency());
}
}
What the framework provides
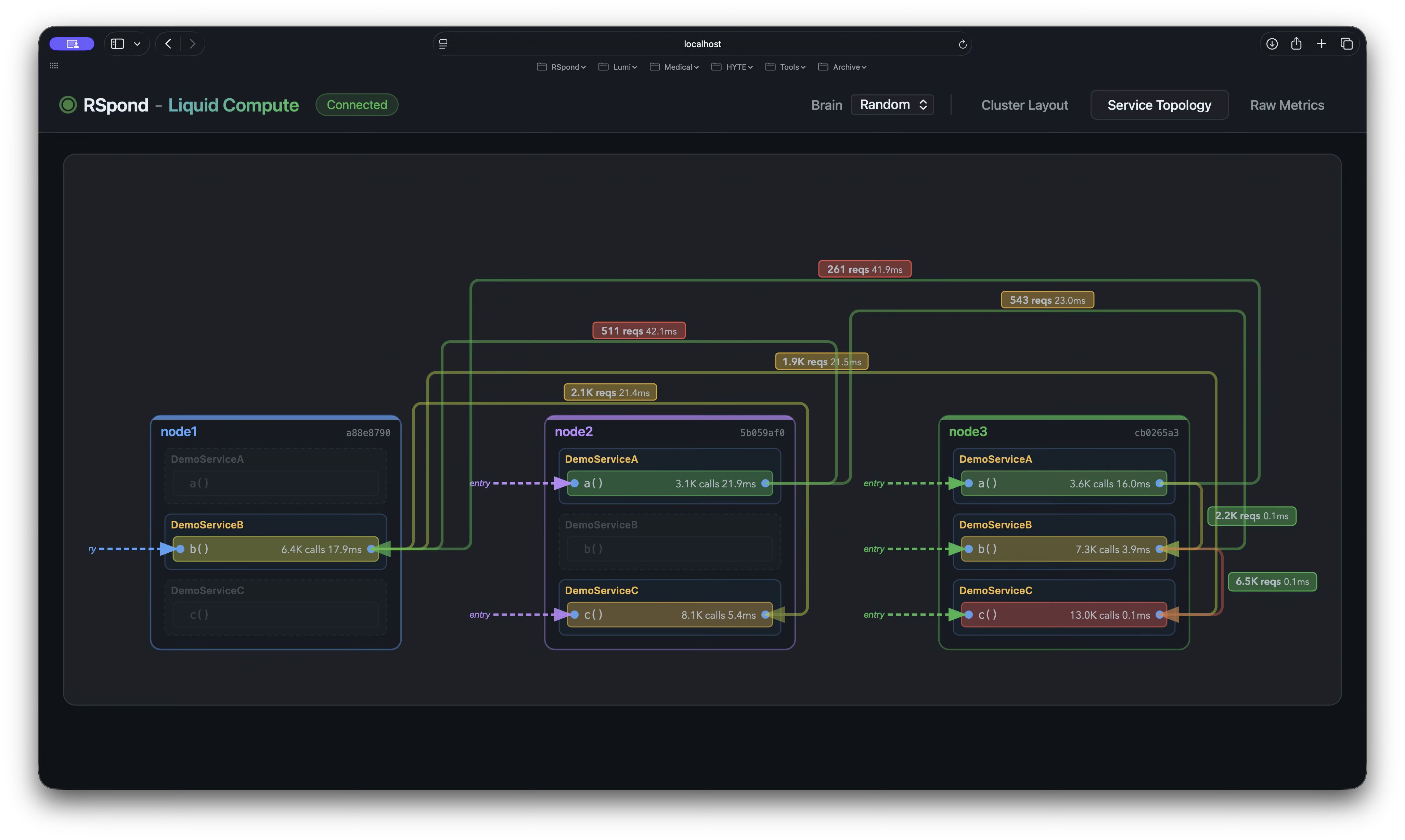
When another service calls pricingService.calculatePrice(order):
- The proxy checks the routing table
- If this node is active for
PricingService, it invokes the local bean directly
- If another node is active, the call is serialized, sent over JMS, and the result is deserialized for you
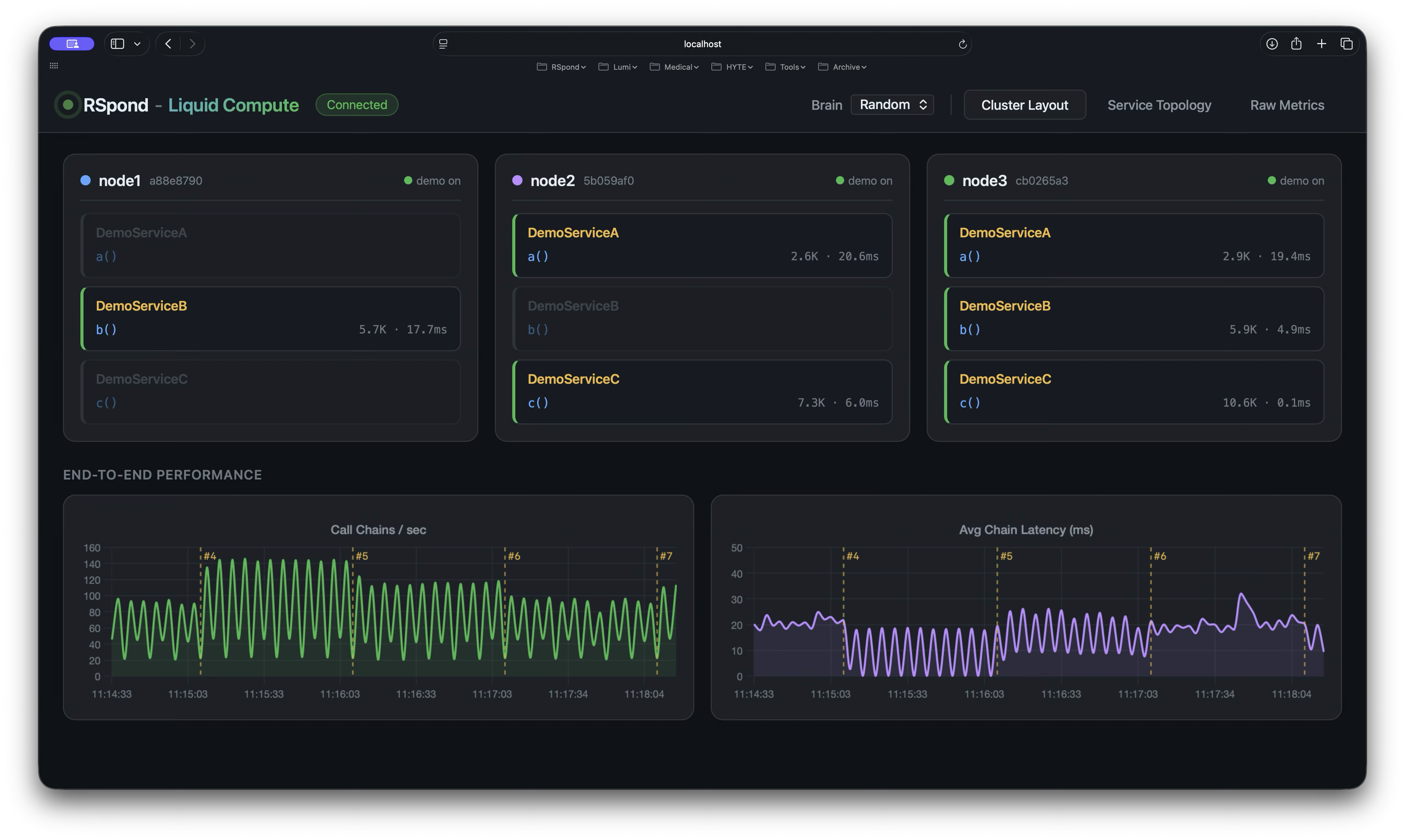
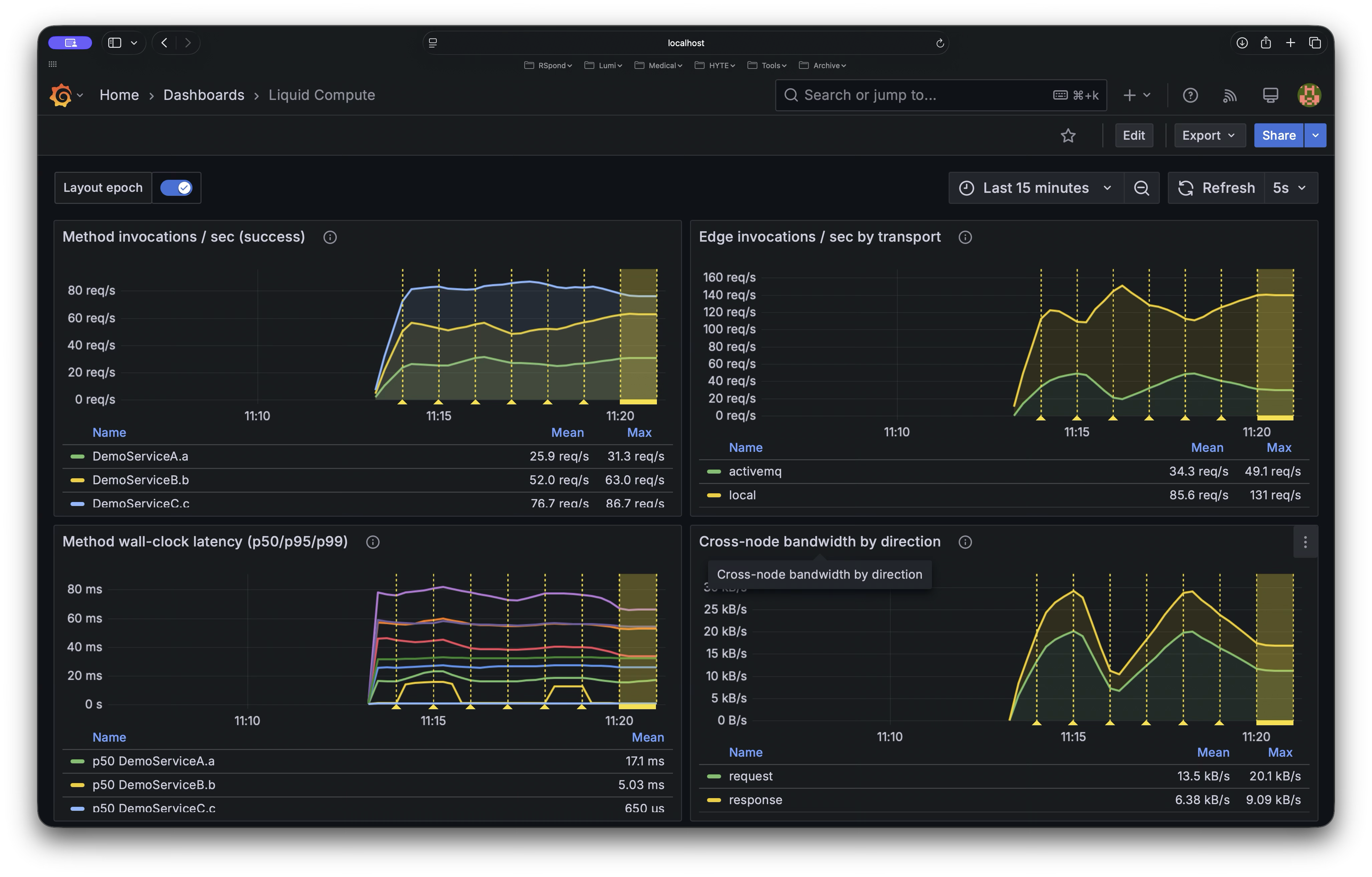
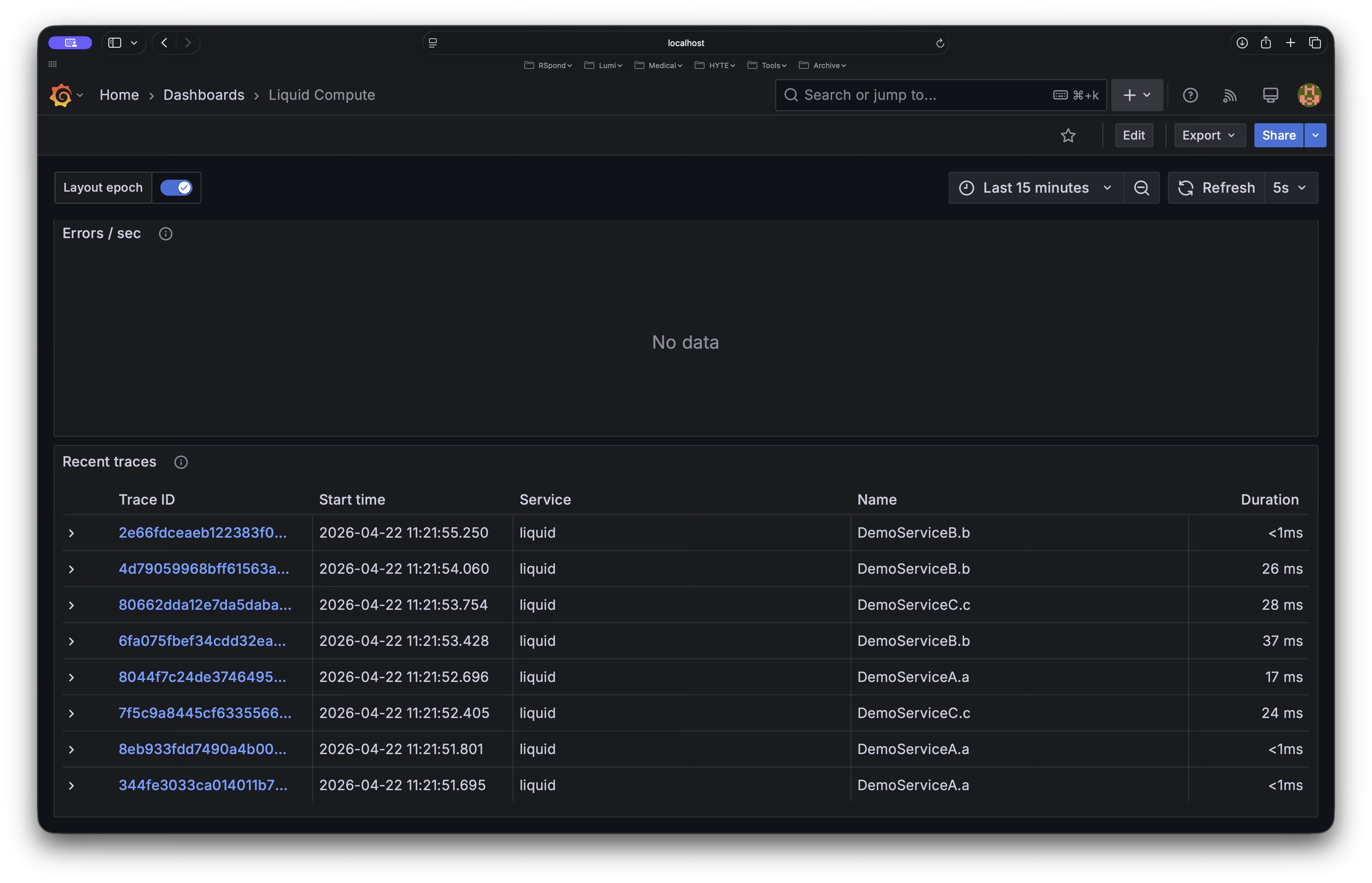
- OpenTelemetry traces the full call chain across nodes
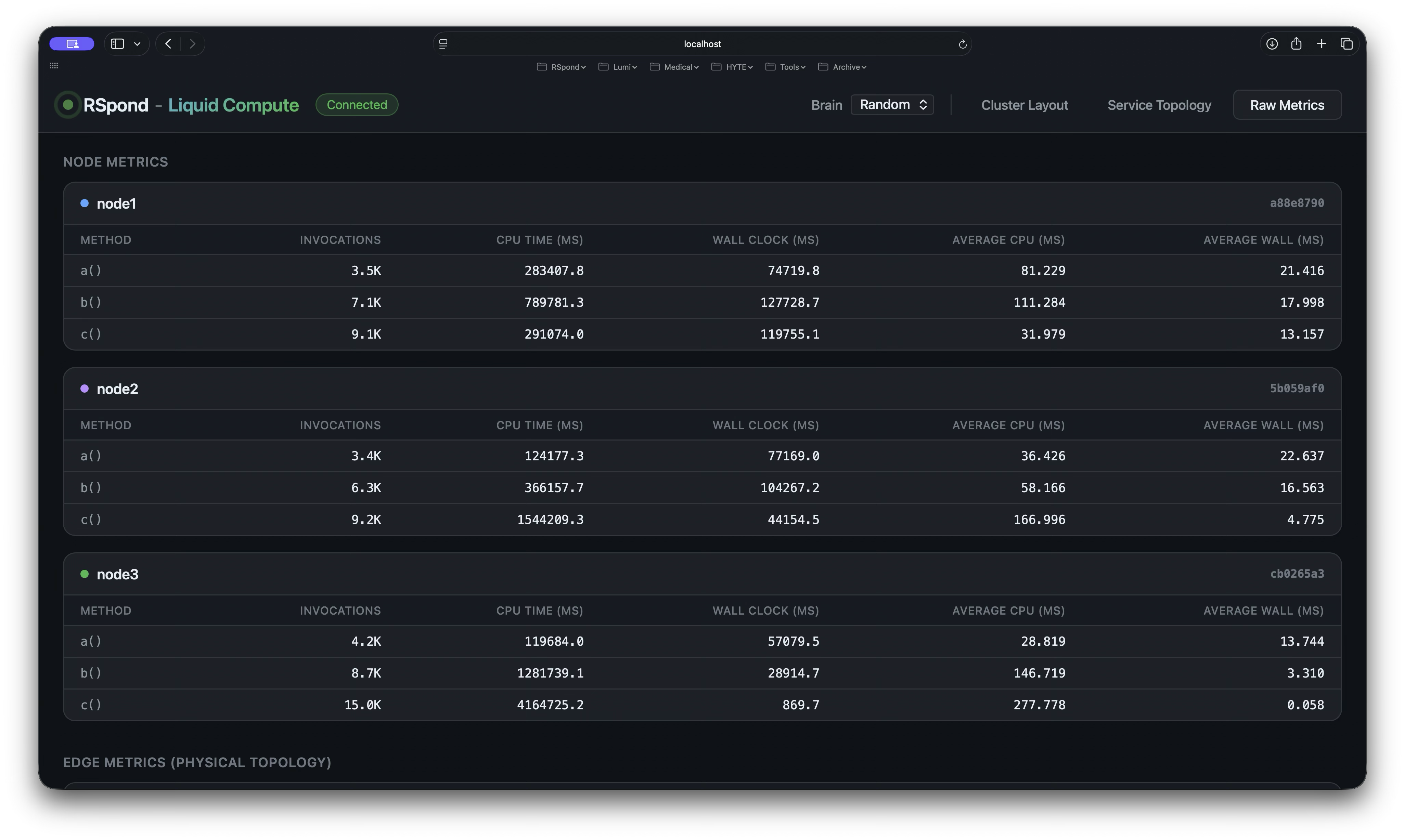
- Micrometer records invocation count, CPU time, and latency
- The dashboard shows it in real time
Same return type, same exception semantics, same trace context — whether the call is local or remote. The framework provides transparent routing, serialization, tracing, metrics, the dashboard, and live rebalancing — all without changes to PricingServiceImpl.