Liquid Compute is a Spring Boot library that makes Java services flow where they’re needed. You write a normal Java interface, annotate it with @Liquid, and implement it as a Spring bean. The framework wraps the bean in a transparent proxy. At call time, the proxy reads a distributed routing table and decides whether to invoke locally or forward the call to another node — same return type, same exceptions, same trace context either way.
No sidecar. No separate control plane. No custom wire protocol. The framework runs inside the application process and uses standard JMS for transport and Hazelcast (or Kubernetes CRDs) for coordination.
The Four Pieces
Four cooperating components make a Liquid cluster work. Each is small, replaceable, and explicit.
In-JVM call interceptor
Every call to a @Liquid interface passes through a lightweight proxy embedded in the JVM. It reads the active layout, then routes accordingly:
Local — invoke the bean directly.
Remote — serialize arguments with Gson, send over JMS, deserialize the response. The caller never knows the difference.
Pluggable scheduling strategy
The brain decides which nodes serve which services. It runs on an interval (or on demand) and proposes a new layout. Two strategies ship today — Random (rotates assignments) and Manual (operators toggle from the dashboard).
A separate mode setting is independent of strategy: AUTO executes proposals immediately, MANUAL waits for operator approval.
Distributed active layout
The active layout is a cluster-wide map: for every @Liquid service, which nodes are currently assigned. It lives in Hazelcast (or as Kubernetes CRDs under a control-plane operator) and is read by every proxy on every call.
Each layout has an epoch — a monotonically increasing number that appears in metrics, traces, and Grafana annotations so you can correlate performance with rebalancing.
Two-phase, stability-preserving moves
When the brain rebalances, the change decomposes into a sequence of individually-safe moves. Each move runs as DEACTIVATE → ACTIVATE: losing nodes finish in-flight requests and stand down, then gaining nodes start serving.
The stability invariant guarantees at least one replica of every service stays active throughout. No traffic blackouts during rebalancing.
The Developer's View (30 seconds)
Write an interface. Add @Liquid. Implement it as a Spring bean. Deploy multiple instances. Done.
PricingServiceImpl.
The Service Cascade
The reference demo runs three services that compose naturally — x³ = x · x². CubeService calls SquareService and MultiplyService; SquareService calls MultiplyService. This is a real 3-deep call chain that exercises cross-node routing, trace propagation, and per-method metrics.
The resulting call chain — with each arrow potentially crossing a node boundary:
cube(3)
└─ multiply(3, square(3))
└─ multiply(3, 3) → 9
└─ multiply(3, 9) → 27
Every arrow that crosses a node is routed by the proxy, traced by OpenTelemetry with W3C Trace Context, and measured by Micrometer. The framework keeps the call surface identical — including exception semantics — so business code stays oblivious to the topology underneath.
How Rebalancing Works
A layout change is not a flag flip. The brain produces a plan — an ordered list of moves — and each move executes in two phases. Operators can run plans all at once, step through one move at a time, regenerate, or stop mid-plan.
Losing nodes stand down
Nodes losing a service stop accepting new traffic for it, finish in-flight requests, and confirm completion. All losing nodes finish deactivating before any gaining node activates.
Gaining nodes take over
Nodes gaining a service open up to traffic and announce activation. The routing table is published with a new epoch; every proxy in the cluster picks it up on the next call.
Invariant
At least one replica of every service stays active through the entire transition. Big rearrangements decompose into a chess game of individually-safe moves — the brain never produces a step that violates the invariant, so services never go down during rebalancing.
Large method results travel via a claim-check pattern: the responding node stores the payload and sends a small reference; the caller fetches it directly. The JMS broker stays fast regardless of payload size.
What You See on the Dashboard
A real-time web dashboard ships with the framework and is served by any node in the cluster. No separate deployment, no extra container.
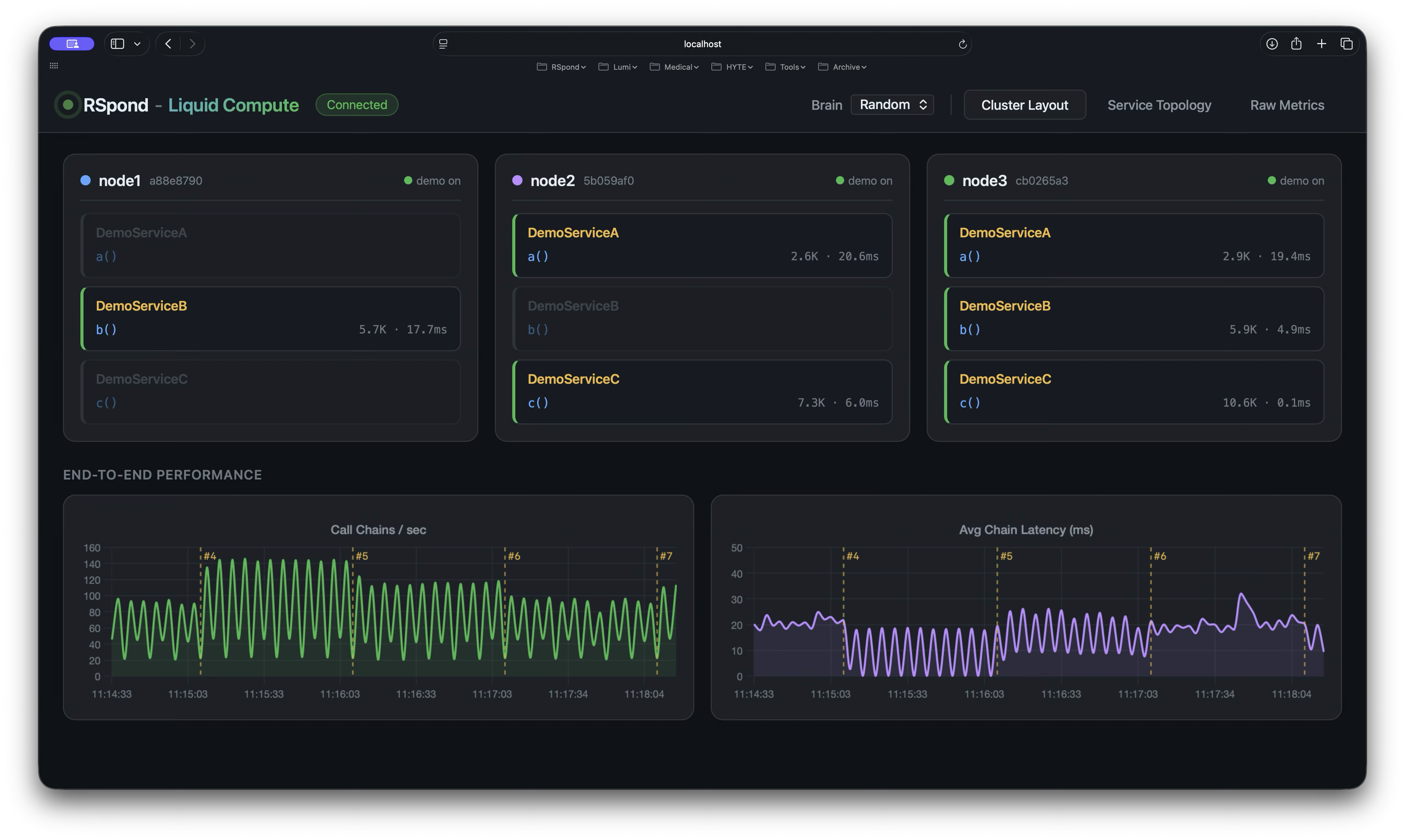
Cluster Layout. A 3-node cluster with services pinned to nodes, per-node RPS, and toggle controls (when the brain is in MANUAL mode). Every move you make appears as a new layout epoch.
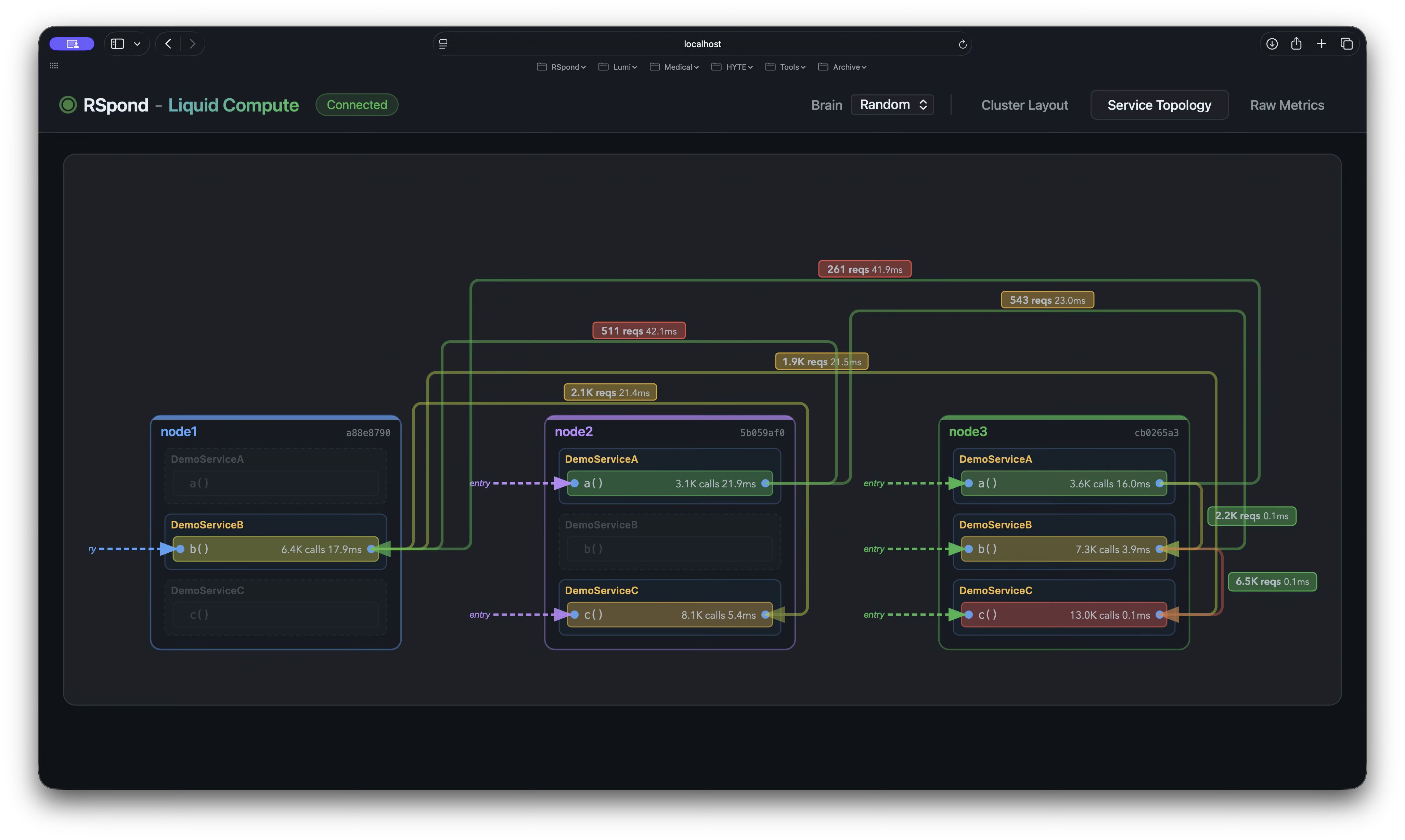
Service Topology. The Cube → Square → Multiply call graph across nodes, with invocation counts and latency on every edge. This is the actual demo cascade running live — not a mock.
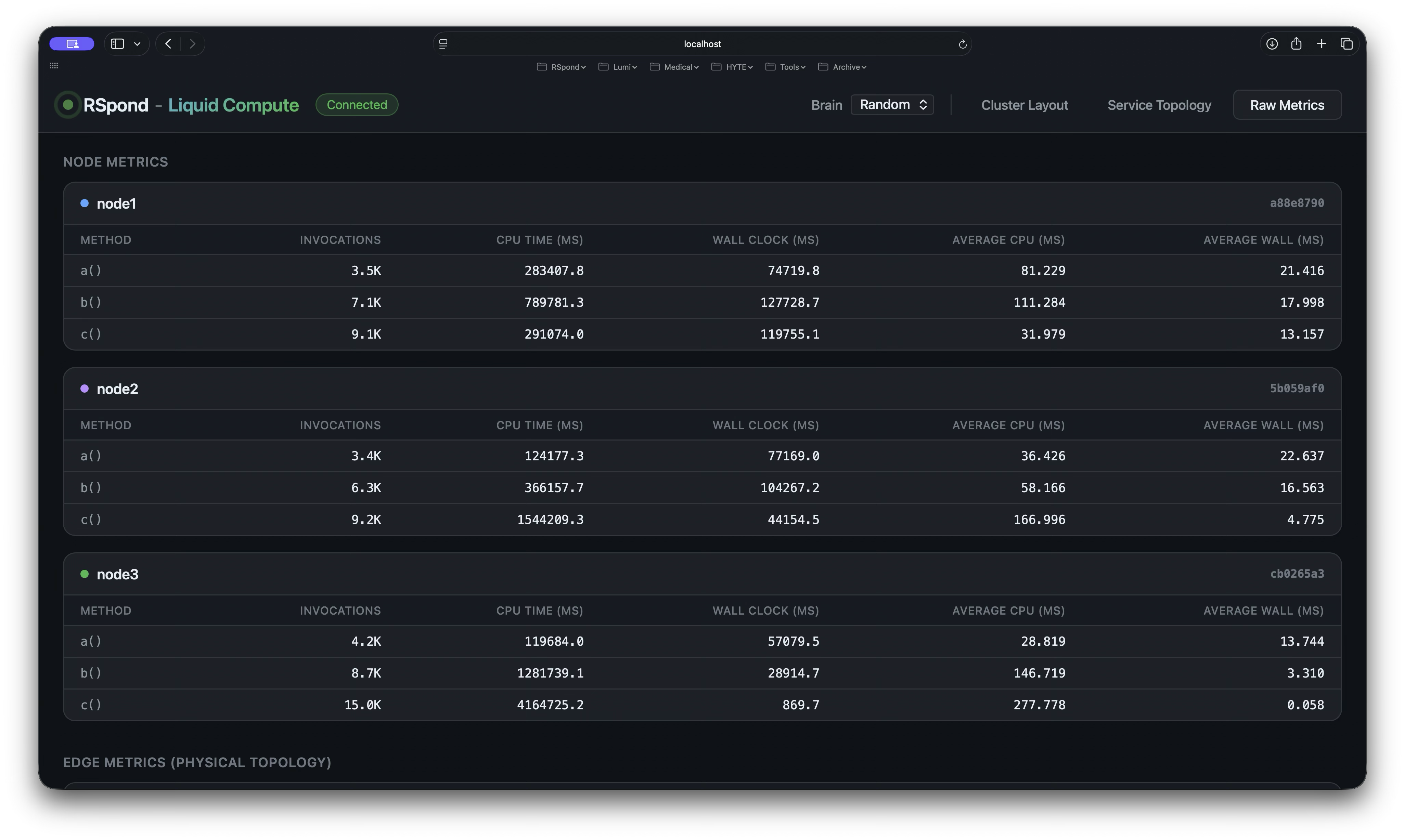
Raw Metrics. Per-method invocation counts, CPU time, and latency tables — sortable, filterable, and exportable for ad-hoc analysis.
- Cluster LayoutService-to-node assignments with manual-mode toggles.
- Service TopologyLive method-to-method call graph with edge weights.
- Performance ChartsReal-time RPS and average chain latency, per node and cluster-wide.
- Brain ControlsStrategy selector, mode toggle, proposal approval, plan stepping.
- Move HistoryEvery move with timestamp, epoch, and outcome — an audit trail of the cluster's life.
End-to-End Observability
Every proxied call produces a Micrometer timer (tagged by service, method, node, and layout epoch) and an OpenTelemetry span. Metrics flow to Prometheus; traces flow to Tempo or any OTLP-compatible collector. Layout epochs appear as Grafana annotations — performance changes line up exactly with rebalancing events.
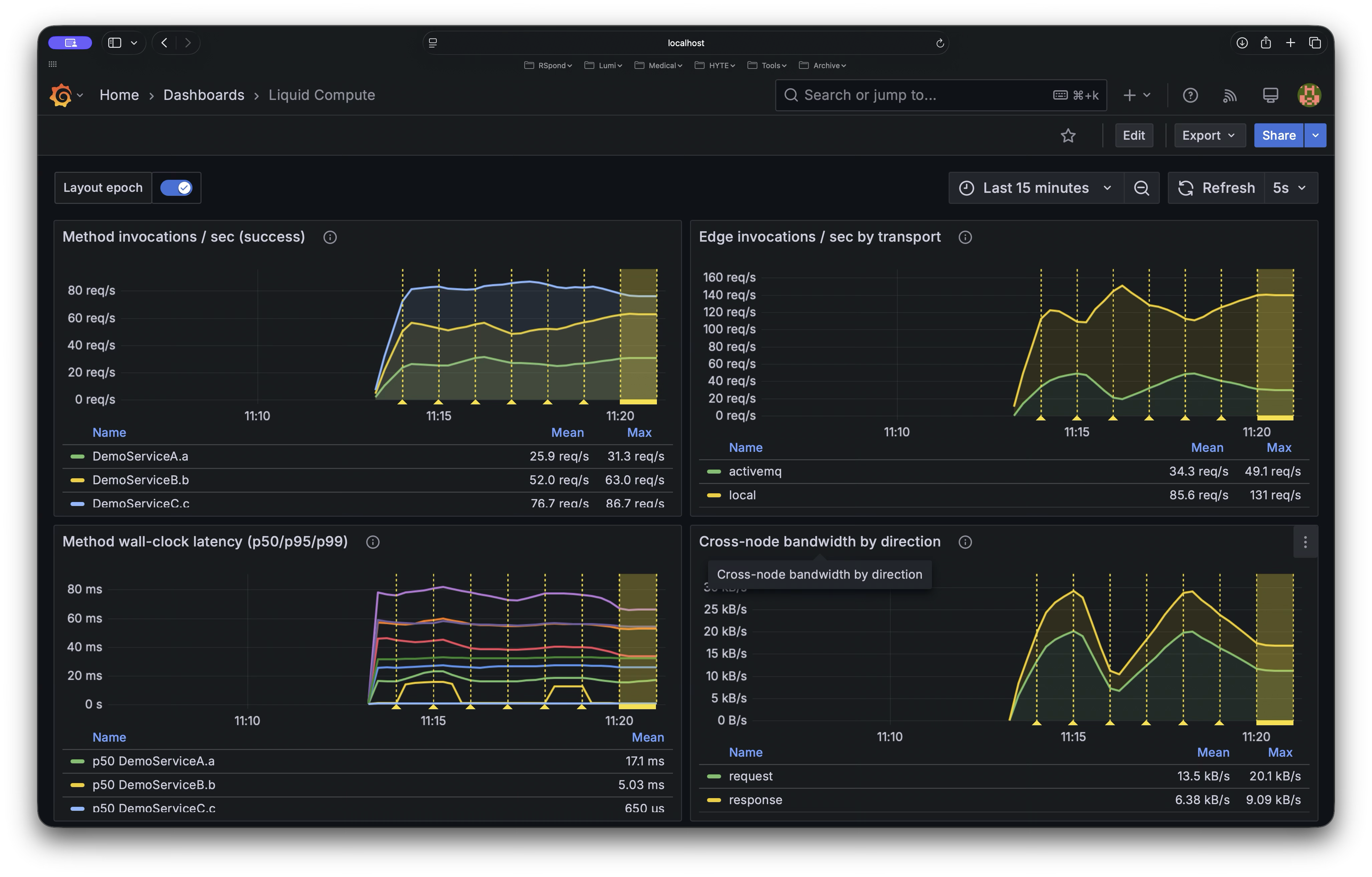
Grafana metrics. Invocations, transport breakdown, latency percentiles, and bandwidth in one view. Layout-epoch annotations let you correlate every dip and spike with a specific move.
Distributed traces. A single request followed across the Cube → Square → Multiply cascade, with timing for each hop including JMS transport and claim-check fetches.
Built With
Liquid Compute composes standard open-source components rather than inventing them. There is no proprietary wire format, no special protocol, no custom storage layer.
Core Framework
- Java
21 LTS - Spring Boot
3.4.4 - Apache Artemis
2.31.2 - Hazelcast
5.3.6 - Gson
Observability
- Micrometer
- Prometheus
- Grafana
- OpenTelemetry SDK
- Grafana Tempo
Kubernetes (optional)
- JOSDK operator
- Custom CRDs
- k3d (local)
- Maven
- JUnit 5